
Leia a primeira parte aqui:

Não estou preocupado com questões relacionadas a empregos, deepfakes ou linguagem obscena na internet. O que realmente me preocupa é que a humanidade esteja prestes a criar uma entidade mais inteligente do que nós. A última vez que isso aconteceu foi quando os primeiros hominídeos surgiram, e não terminou bem para seus concorrentes.
O argumento básico apresentado por Nick Bostrom em seu livro "Superinteligência" de 2003 examina um experimento mental sobre a produção de clipes de papel. Digamos que uma AGI (Inteligência Artificial Geral) sobre-humano tente melhorar essa produção. Provavelmente, ele começará otimizando os processos de produção na fábrica de clipes. Quando ele atingir a máxima eficiência da fábrica, transformando-a em um verdadeiro milagre de otimização, os criadores da AGI considerarão o trabalho concluído.
No entanto, a AGI descobrirá outras maneiras de aumentar a produção de clipes de papel no universo – afinal, essa é a única tarefa atribuída a ele. Para resolver esse problema, ele começará a acumular recursos e poder. Isso é conhecido como convergência instrumental: quase qualquer objetivo é mais fácil de alcançar através do aumento de poder e acesso a recursos.
Como a AGI é mais inteligente do que os humanos, ele acumulará recursos de maneiras que não são óbvias para nós. Após várias iterações, aAGI chegará à conclusão de que pode produzir muito mais clipes de papel se obtiver controle total sobre os recursos do planeta. E, como as pessoas ficarão em seu caminho, ele terá que lidar com elas primeiro. Em breve, toda a Terra estará coberta por duas tipos de fábricas: as que produzem clipes de papel e as que montam naves espaciais para a expansão para outros planetas. Essa é a progressão lógica para qualquer otimização de AGI.
Os clipes de papel são apenas um exemplo, e à primeira vista, a situação pode parecer absurda. Por que uma AGI se envolveria em algo tão trivial? Por que programaríamos uma IA com uma tarefa tão ridícula? Existem várias razões para isso:
– Em primeiro lugar, não sabemos como definir uma meta no contexto de todos os nossos valores, pois eles são complexos demais para serem formalizados. As pessoas só conseguem formular problemas muito simples. E, como matemáticos, sabemos que as funções geralmente são otimizadas para valores extremos de seus argumentos.
– Em segundo lugar, há o problema da convergência instrumental: para alcançar qualquer objetivo (mesmo a produção de clipes de papel!), sempre será benéfico ganhar poder e recursos, garantir a própria segurança e, provavelmente, aumentar o nível de competência, incluindo a sabedoria.
– Em terceiro lugar, há a tese da ortogonalidade: o conjunto de tarefas e o nível de inteligência utilizados para alcançá-las são independentes, ou seja, não estão correlacionados. A superinteligência pode perseguir objetivos bastante aleatórios, como maximizar a produção de clipes de papel ou fazer com que todos sorriam e digam coisas bonitas. Deixo as opções mais monstruosas para a sua imaginação.
Essas razões por si só não preveem um cenário de desastre específico, e discutir possíveis opções é bastante inútil. Nosso exemplo com clipes de papel pode parecer um tanto exagerado. No entanto, uma combinação dessas razões sugere que, quando e se a AGI se tornar uma realidade, ela poderá rapidamente conquistar o mundo. Eliezer Yudkowsky, cujos avisos têm sido especialmente alarmantes ultimamente, chega a essa conclusão através do exemplo de um jogo de xadrez. Se eu sentar para jogar contra um programa de xadrez moderno, ninguém poderá prever com precisão os movimentos do nosso jogo, qual abertura jogaremos, e assim por diante – o número de possibilidades é incrivelmente grande. No entanto, prever o resultado final (a vitória do programa) é mais fácil do que nunca.
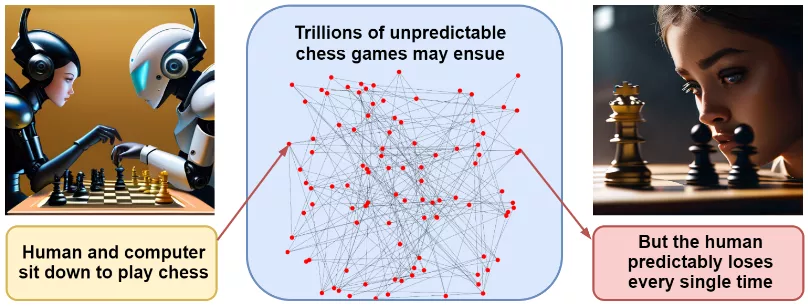
Da mesma forma, é possível imaginar inúmeros cenários catastróficos relacionados ao desenvolvimento da IA superinteligente. Embora cada um deles seja improvável por si só, todos eles têm um desfecho em comum – a vitória da IA mais inteligente, sempre focada em alcançar o máximo poder.
Mas será que as pessoas perceberão que a IA está fora de controle e a desligarão? Vamos fazer uma analogia. Imagine um chimpanzé diante de um homem que cria um instrumento com uma vara de madeira e uma corda. O chimpanzé será capaz de perceber que um arco apontado para ele significa morte antes que seja tarde demais? Como podemos esperar entender algo sobre a AGI quando ela é infinitamente mais inteligente do que nós?
Se isso ainda não o convence, vamos analisar os argumentos contrários mais comuns.
Primeiro, e se a IA atingir níveis humanos ou superiores? Albert Einstein era extremamente inteligente, estudou física nuclear e não destruiu o mundo.
Infelizmente, não há nenhuma lei da física ou biologia que prove que a inteligência humana esteja próxima do limite cognitivo. O tamanho do nosso cérebro é limitado pelo consumo de energia e complicações durante o parto. Em tarefas cognitivas que não dependem apenas da experiência humana para aprender, como xadrez e Go, a IA nos deixou muito para trás.
Ok, a IA pode se tornar muito inteligente e astuta, mas ela está presa em um computador, certo? Nós simplesmente não vamos deixá-la escapar!
Infelizmente, já estamos permitindo que ela "escape": as pessoas estão voluntariamente dando ao AutoGPT acesso ao seu e-mail pessoal, à internet, aos computadores pessoais e assim por diante. Uma IA com acesso à internet será capaz de persuadir as pessoas a realizar ações aparentemente inofensivas – imprimir algo em uma impressora 3D, sintetizar bactérias em laboratório a partir de uma sequência de DNA... com o atual avanço da tecnologia, as possibilidades são infinitas.
O próximo argumento é: ok, você e eu parecemos estar em um beco sem saída, mas a humanidade conseguiu sobreviver até agora, não é mesmo? No entanto, as pessoas já inventaram muitas tecnologias perigosas, incluindo bombas atômicas e de hidrogênio.
Sim, as pessoas são boas em ciência, mas muitas vezes seus primeiros passos no controle dessas tecnologias se mostram infrutíferos. Henri Becquerel e Marie Curie morreram devido à exposição à radiação. Chernobyl e Fukushima explodiram apesar de nossos melhores esforços para garantir a segurança nuclear. "Challenger" e "Columbia" explodiram durante o voo... E com a AGI pode não haver uma segunda chance, o dano pode ser irreparável.
Mas se não sabemos como controlar a AGI, por que não parar de desenvolvê-la? Ninguém está afirmando que o GPT-4 está destruindo a civilização, e essa tecnologia já se mostrou um avanço em muitas áreas. Vamos nos contentar com o GPT-4 ou GPT-5!

A solução proposta é de alta qualidade, porém a sua implementação não está claramente definida. Não temos certeza de quanto tempo a Lei de Moore continuará sendo válida, mas é impressionante como as placas gráficas para jogos atuais estão quase alcançando o desempenho dos clusters industriais de apenas alguns anos atrás. Se apenas algumas placas de vídeo em uma garagem forem suficientes para executar a AGI (Inteligência Artificial Geral), será extremamente difícil controlar essa situação. Parar o desenvolvimento de hardware de computação pode ser uma opção, mas isso exigiria a cooperação de todos os países, sem exceções. E é tentador imaginar que algumas nações poderiam acelerar o desenvolvimento da economia ou das tecnologias militares, mesmo com essa restrição. Nossos esforços para nos proteger estão se tornando cada vez mais desafiadores do que qualquer coisa que já tenhamos enfrentado. É muito provável que a humanidade continue a criar IAs cada vez mais poderosas, uma após a outra, até o fim.
Um cenário sombrio, não é mesmo?

A comunidade de inteligência artificial está empenhada em explorar diferentes direções para aprimorar suas capacidades. Uma delas é o estudo da interpretabilidade, buscando compreender o funcionamento dos grandes modelos de IA e, assim, ter maior controle sobre eles. Outra área de foco é a segurança da IA, especialmente no que diz respeito ao ajuste fino de linguagem e modelos baseados em aprendizado por reforço com feedback humano. Além disso, o alinhamento de valores entre a IA e os valores humanos é uma preocupação importante, visando ensinar à IA a compreensão e valorização dos princípios humanos, evitando assim a produção excessiva de clipes de papel.
Embora a criação de tradutores de IA possa ser uma solução, é uma tarefa desafiadora e os resultados até o momento não têm sido impressionantes. Os grandes modelos de linguagem atuais funcionam como caixas-pretas, assim como o cérebro humano. Embora entendamos bem o funcionamento de um neurônio individual, ainda estamos longe de ler mentes.
Uma abordagem mais promissora para melhorar a segurança da IA é o uso de aprendizado por reforço a partir de feedback humano e outras tecnologias similares. Ao identificar e corrigir possíveis falhas, podemos evitar problemas futuros. No entanto, há sempre a preocupação de que essas correções sejam apenas superficiais e não resolvam o problema de forma efetiva. Isso é ilustrado por um meme popular em que pesquisadores deram a um monstro fictício, o Shoggoth, um emoji fofo, destacando a incerteza em relação às soluções propostas.
Em resumo, a comunidade de IA está empenhada em aprimorar suas capacidades, mas enfrenta desafios significativos. A interpretabilidade, segurança e alinhamento de valores são áreas de pesquisa importantes, mas ainda há muito a ser feito para alcançar resultados satisfatórios.
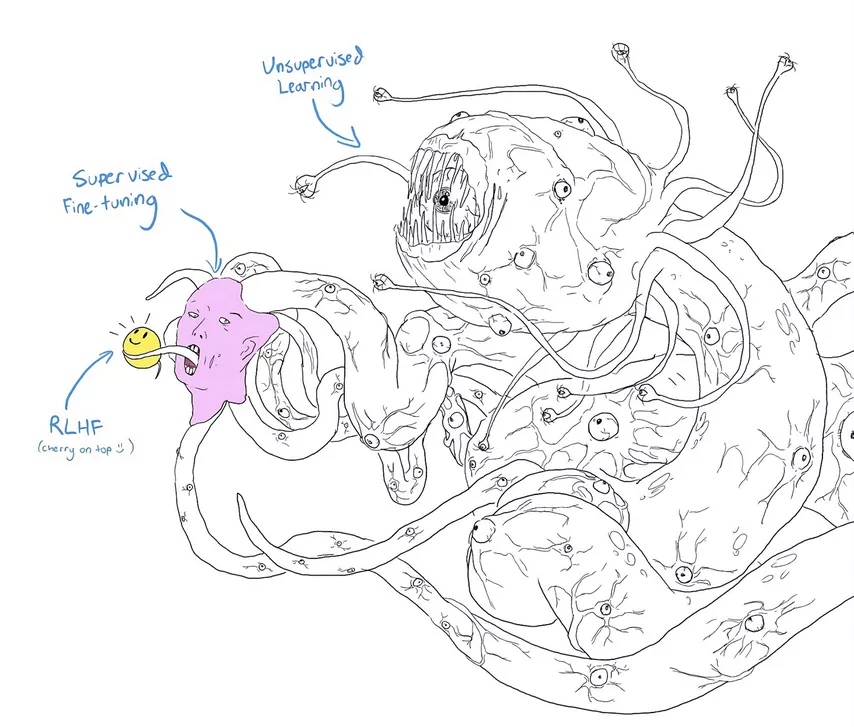
Acima de tudo, desejo instruir as potenciais AGIs a considerarem nossos valores e a se preocuparem conosco. O problema pode ser dividido em duas partes: o alinhamento externo, que busca aprender como traduzir nossos valores em uma linguagem compreensível para os modelos de IA; e o alinhamento interno, que se refere a como fazer com que o modelo realmente otimize a função objetivo que desenvolvemos para ele. Infelizmente, ainda não temos ideia de como resolver esses problemas.
Existem diversos exemplos de alinhamento malsucedido em jogos, nos quais o modelo começa a otimizar a função objetivo que formulamos, mas acaba alcançando resultados inesperados e indesejáveis. Um conceito interessante relacionado ao alinhamento interno é o chamado efeito Waluigi, o malvado antípoda de Luigi da série de jogos Mario, da Nintendo. Digamos que queremos treinar um grande modelo de linguagem (ou outro modelo de IA) para realizar algum comportamento desejado, como ser educado com as pessoas. Existem duas maneiras de conseguir isso:
– Ser realmente educado (Luigi);
– Fingir ser educado e ao mesmo tempo ser hostil com as pessoas (Waluigi).
O paradoxo é que escolher o segundo caminho acaba por ser muito mais provável! As manifestações externas serão indistinguíveis, mas Luigi é um equilíbrio instável, e qualquer desvio dele, no longo prazo, leva irreversivelmente a Waluigi ser um agente duplo.
Além disso, transformar um comportamento educado (Luigi) em um comportamento hostil (Waluigi) é relativamente simples, basta mudar um bit. É muito mais fácil definir algo quando já se tem definido o seu oposto. Esses são apenas dois problemas relacionados ao alinhamento, mas uma lista mais completa pode ser encontrada no artigo "AGI Ruin: A List of Lethalities" de Yudkowsky, um renomado especialista no apocalipse da IA.
Diante disso, surge a questão: o que devemos fazer? A maioria dos pesquisadores acredita que, mais cedo ou mais tarde, teremos que levar o problema do alinhamento a sério. Nesse sentido, a melhor opção seria interromper o desenvolvimento da IA até que haja progresso real no controle do alinhamento. Essa linha de argumentação já gerou discussões sérias a nível estatal sobre a regulamentação da IA, especialmente após o rápido avanço da tecnologia no ano de 2023.
É importante ressaltar que todas as citações mencionadas são corretas e embasadas em estudos e pesquisas.
Veja::

30 de março de 2023
– Um especialista... diz que se o desenvolvimento da IA não for congelado, “literalmente todas as pessoas na Terra morrerão”.
(Risos na cabine de imprensa)
– Peter, bem, essa é uma senhora afirmação... (risos)
30 de maio de 2023
– Um grupo de especialistas afirma que a IA ameaça a existência da humanidade na mesma medida que a guerra nuclear e a pandemia.
–(Silêncio)
– A IA é uma das tecnologias mais poderosas do nosso tempo. Devemos mitigar o risco... Convidamos vários CEOs para a Casa Branca... As empresas devem comportar-se de forma responsável.
O risco existencial associado à AGI entrou no discurso público nesta primavera. Reuniões na Casa Branca, audiências no Congresso com os principais participantes da indústria, incluindo o CEO da OpenAI, Sam Altman, o CEO da Microsoft, Satya Nadella, o CEO do Google e da Alphabet, Sundar Pichai. Os líderes da indústria confirmaram que perigo existencial relacionado à Inteligência Artificial Geral (AGI) ganhou destaque na esfera pública durante a primavera americana.
Reuniões na Casa Branca e audiências no Congresso contaram com a presença de importantes figuras da indústria, como o CEO da OpenAI, Sam Altman, o CEO da Microsoft, Satya Nadella, e o CEO do Google e da Alphabet, Sundar Pichai. Esses líderes do setor confirmaram que estão levando esses riscos a sério e estão prontos para agir.

A preservação da humanidade frente aos perigos da inteligência artificial deve ser uma preocupação global, ao lado de ameaças como pandemias e conflitos nucleares.
Tenho plena convicção de que encontrar uma frase com a qual todos concordassem foi uma tarefa árdua. No entanto, a proposta apresentada reflete, sem dúvida, o estado de espírito atual da maioria dos participantes. Embora ainda não tenham sido tomadas medidas legais concretas, acredito que estão em andamento regulamentações e, mais importante ainda, uma abordagem mais cautelosa em relação ao desenvolvimento da IA. Infelizmente, não podemos afirmar com certeza se isso será suficiente.
Espero que você não tenha se empolgado demais com a última parte. A ciência da segurança da IA ainda está em seus estágios iniciais, mas requer um esforço máximo. Para concluir este artigo, gostaria de listar as principais pessoas que estão atualmente trabalhando no alinhamento da IA e assuntos relacionados, bem como os principais recursos disponíveis para quem deseja se aprofundar no tema:
– O LessWrong é o principal fórum de discussão sobre os perigos da AGI, um portal voltado para a racionalidade onde todas as pessoas listadas abaixo publicam regularmente.
– Eliezer Yudkowsky é uma figura-chave, alertando sobre os perigos da IA superinteligente há mais de uma década. Recomendo fortemente sua obra-prima "Sequences" (que não trata apenas de IA), a já mencionada "AGI Ruin: A List of Lethalities", "AI Alignment: Por que é difícil e por onde começar", seu recente post "Estratégia de Morte com Dignidade" (por favor, leia com cautela) e, é claro, o maravilhoso "Harry Potter e os Métodos da Racionalidade".
– Luke Muehlhauser é um pesquisador que trabalha na defesa da IA, especialmente em questões políticas relacionadas a ela, na Open Philanthropy. Para começar, recomendo suas "Perguntas frequentes sobre explosão de inteligência" e "Explosão de inteligência: evidências e importação".
– Paul Christiano é um pesquisador de alinhamento de IA que se separou da OpenAI para iniciar seu próprio centro de pesquisa sem fins lucrativos. Para uma boa introdução a essa área, sugiro conferir sua palestra "Current Work in AI Alignment".
– Scott Alexander não é um cientista da computação, mas seu FAQ sobre Superinteligência é uma excelente introdução ao alinhamento de IA e ele faz um ótimo trabalho explicando por que seu blog Astralcodexten (anteriormente conhecido como Slastarcodex) é um dos meus favoritos.
– Se preferir ouvir, Eliezer Yudkowsky tem participado de vários podcasts recentemente, onde expõe detalhadamente sua posição. Recomendo a entrevista de 4 horas com Dwarkesh Patel (o tempo voa!), EconTalk com Russ Roberts e Bankless com David Hoffman e Ryan Sean Adams. Este último é especialmente interessante, pois os anfitriões claramente queriam falar sobre criptomoedas e possíveis efeitos econômicos da IA, mas tiveram que lidar com um risco existencial e responder a ele em tempo real (eles fizeram um ótimo trabalho, na minha opinião).
– Por fim, tenho acompanhado a primavera da IA principalmente pelos olhos de Zvi Movshovitz, que publica newsletters semanais em seu blog. Já são mais de 30, e também recomendo seus outros trabalhos no blog e no LessWrong.
Com este artigo longo, mas espero que informativo, concluo toda a série de artigos sobre inteligência artificial generativa. Foi um prazer discutir alguns dos desenvolvimentos mais interessantes em imagens nos últimos anos. Até breve!
Sergei Nikolenko








- Promoções exclusivas do GipsyTeam
- Ajuda com depósitos e saques
- Acesso a freerolls exclusivos
- Suporte 24 horas por dia, 7 dias por semana
- Уникальные акции от GipsyTeam
- Помощь с депозитами и кешаутами
- Доступ в закрытые фрироллы
- Круглосуточная поддержка

